Anyone who has used the ERwin Model Manager in the past decade has probably spoken to Matt over in the support team. I know that he has saved my bacon on quite a few occasions and is probably the number one resource for all things "Mart-related". Well, it turns out that he has been blogging on the CA Community pages and I wanted to promote some of his tips to all of you following this blog.
Matt's most recent post deals with a performance enhancement to the Model Manager in ERwin 8.1 and the recent ERwin 7.3.11 release. Basically, by enabling...
ERWIN_INC_ORACLE_FETCH_BUFFER = true
...there is a significant improvement of performance on the Model Manager data retrieval (about 1.5 times) when using Oracle or Sybase as the repository server. This is yet another reason to upgrade to 8.1. Be sure to read my previous post for more 8.1 features.
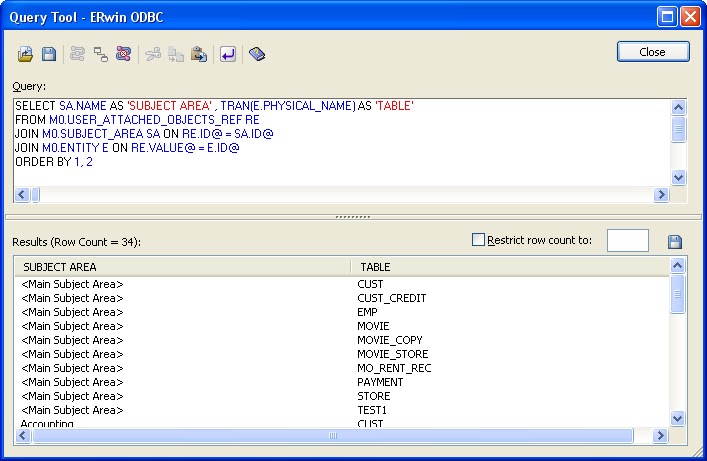
In this useful post Matt outlines a query that can be run against the Model Manager that will return all the model names as well as their target servers. For anyone that ever wanting a full report of the models and target servers without having to run individual reports, this is going to be a real time saver. The query is for SQL Server but can easily be modified for Oracle, as well.
This technical document is a great resource for specific techniques that will greatly improve your Model Manager workflow. Nearly all the techniques outlined are at the user (ERwin client) level. So if you are not making any headway with tweaking your server settings (or getting your team to roll out an upgrade) you can probably achieve huge performance improvements simply by implementing a few best practices and process changes.
The techniques described, include auto filtering all object types (like all graphics) with a single option change, within the action log, itself. This is a pain point that users are often unaware has such a simple solution.
Also, the technique of saving files offline if there are extensive changes to be made is my personal process and a suggestion I make to anyone who asks for my performance enhancement suggestions. By saving files offline, you bypass such issues of:
- Losing changes due to network failure.
- Performance bottlenecks when everyone attempts to save their files simultaneously (lunch, end of day).
- Prevents the creation of many unwanted version due to repeated incremental saves.
Little process changes can have big impact on your time to project's bottom line.
A few years back, Matt also published this article which outlines Model Manager tuning suggestions. This article is also part of the Bookshelf that is included as part of your ERwin installation.
Lastly, since we are on the topic of improving the model manager performance, I'd like to suggest an index of my own. This one has been floating around for some time (I worked on it back when I was in CA Support). It is very simple and in my experience it has improved my Model Manager performance 20 fold. I recently worked with a client that had an identical performance boost so I think I will post it, again. Worst case scenario, you will have 0% improvement in performance enhancement and you can simply drop the index, if that is the case. The index is as follows:
-----Oracle Script---------
CREATE INDEX XAK3_MASTVERS ON m7object
(
MASTERID ASC,
STARTVERSION ASC
)
LOGGING
TABLESPACE ; -- Replace with the name of your Data Tablespace (e.g. MMADMIN).
---------End Oracle Script
------Sql Server Script------
CREATE INDEX XAK3_MASTVERS ON m7object
(
MASTERID ASC,
STARTVERSION ASC
)
Go
----End Sql Server Script---------
Make sure to subscribe to Matt's blog and to check out CA's weekly Tuesday Tips for more insight from the CA technical community.